
Arguably one of the greatest innovations within the Global BGP routing system in the last decade is one that you probably never have to deal with. Continue Reading
Arguably one of the greatest innovations within the Global BGP routing system in the last decade is one that you probably never have to deal with. Continue Reading
Some of the most flexible aspects of Interoute’s VDC can be considered both strong points and weak points. It’s great to be able to create subnets and VLANs with a single click, and then effortlessly connect them to either the Internet or a private WAN, but sometimes the flexibility afforded allows one to forget fundamental primitives, such as KISS, and shoot oneself in the foot.
In some of the engagements I’ve worked on, I’ve seen virtual network diagrams that could really win awards on Rate My Network Diagram-type web sites, but they may not be appropriate for mission-critical apps in cloud networks where simplicity and reliability matters most.
Tech Editor’s Note For those unfamiliar, Rate My Network Diagram was a fun community-based web site for sharing – and likely shaming – complex network diagrams between engineers. Google’s image cache offers us a glimpse of what might have made it there:
Part of the problem is that we’re still very used to designing networks based upon discrete physical hardware that has its own costs, capabilities and limitations. But network virtualisation changes the rules, and makes some of our previous assumptions look foolish and wrong.
Here I present some guidelines or axioms to help guide enterprise users in creating cloud-based apps that integrate nicely with enterprise networks with the least amount of gotchas.
This is crucially important. What we mean here is determine the centre of your network first of all and make sure that this element has real network power and isn’t virtual.
VM-based network appliances (firewalls, load balancers etc) are a huge boon for rapidly deploying capabilities to manage, monitor and manipulate network traffic but they also represent a significant pinch point and as such they limit the number of end-hosts that can be supported.
Interoute’s VDC helps here because it enjoys an intimate fusion with Interoute’s carrier-grade MPLS-based IP network that is able to carry both Internet and private network services in parallel with little difference.
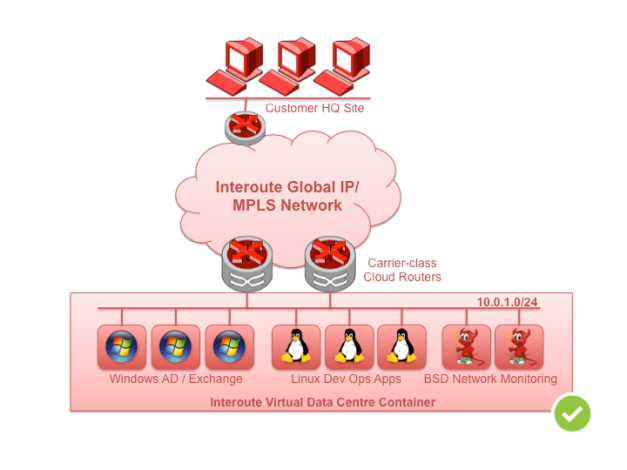
Fig 1. Large networks are fine with direct private network access
In the simplest case, an Interoute VDC customer can simply create an IP-layer subnet as large as needed, add it to their private WAN using the VDC Control Panel, and any established virtual machines are pingable as soon they boot. The VDC Control Panel interfaces through Interoute’s innovative IP-layer API to signal the presence of the subnet, and any participating VPN sites immediately become aware of the cloud service.
No need to add static routes to VM-based routers. No need to configure and troubleshoot IPSec tunnels with complicated keys and encryption policies.
Because the cloud workload communicates directly with the real network, performance is limited only by the CPU and I/O capacity that is available to the actual VM.
Even though the ideal situation is to directly attach VMs to the network, sometimes this isn’t possible, or reasonable. The classic case is where one is using VDC to service Internet users and a firewall function is required.
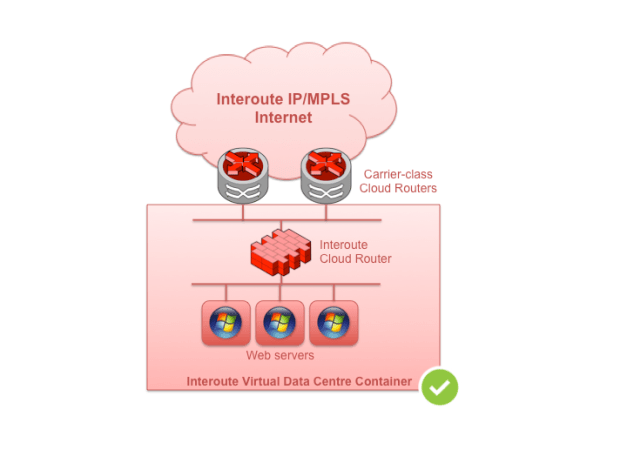
Fig 2. Keep Virtual Router served networks smaller
Without involving any existing private WAN (for which there are optimal solutions using Interoute’s Internet Central service), the easiest option is to place Interoute’s Cloud Router at the head of the subnet. It can seamlessly connect the private cloud network with the Internet and provide the following features:
Alternatively, customers can choose from specialist vendor firewalls or network functions. Regardless of which option is chosen, however, it’s important to realise that the network function is virtual and it’s implemented on a VM, just like any other ordinary workload. Let’s call it a Virtualised Network Function, or a VNF-powered app.
This means that a packet transmitted from your Linux-based Apache web server for example, consumes I/O and CPU resource not just on that VM, but also on the VM hosting the firewall function through which the packet needs to pass.
Technology aside, the virtual compute resources available in VDC are uniform and equal so it’s easy to see how this can become a bottleneck when a VNF has to function for a large number of Virtual Machines.
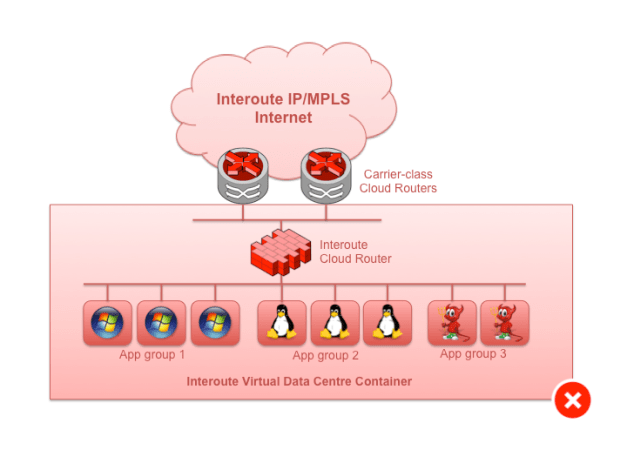
Fig 3. Don’t do this: large subnet dependent on single VNF
VNFs are extremely useful however, so in order to not get trapped in a situation where excessive resources are used, and VM capacity is wasted, we need another rule.
Separate VNF-powered apps into logical groups in order to avoid overpowering VNFs and wasting VM resources. Avoid creating large monolithic subnets with lots of VM server attachments when you know that the gateway serving the subnet is virtual.
The knee-jerk response to this is usually to break things into multiple subnets, but, of course, because you still need the VNF, you end up multi-attaching to that. So that doesn’t really fix the problem.
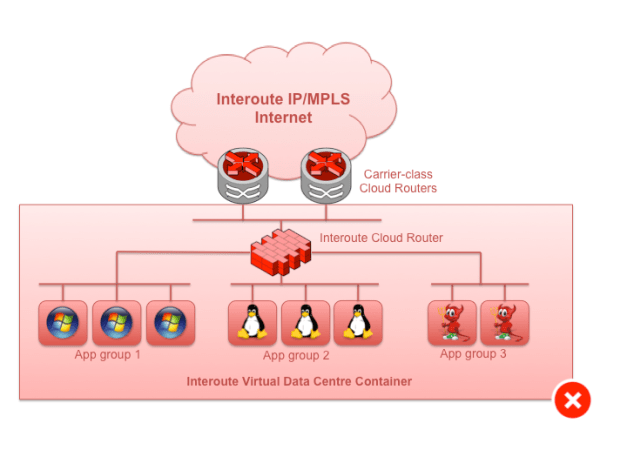
Fig 4. Don’t do this: Multiple small subnets, but the VNF is still acting as the network nexus
Instead of that, replicate the VNF function for each of the subnets / application groups that you want to service. The traditional network function vendors haven’t quite got their heads around this subtlety in the move to a software model.

Fig 5. Do this: separate VNFs for each logical app
This one is a tough one. The usual motivation is a separate out-of-band management access channel to the VM. The problem with multi-homing VMs, though, is that you’ve then got to manage the routing table on the VM and that can easily descend into static route hell.
Static routes are not great because they are just that – static. They don’t adjust with topology, and we need hacks such as VRRP to make them useful. Secondly, you now have two different addresses and associated routing for a single element. That would be fine, but the VM itself has only a single routing table, so asymmetric routing is inevitable for at least one of the two functions the VM is providing: either the main app, or the management channel. Asymmetric routing is the sworn enemy of enterprise-grade firewalls that maintain session state, and getting round that means NAT. Complicated.
So when considering out-of-band management access, remember that the NICs we’re talking about on VMs now are, of course, virtual. They don’t fail in the same way real hardware fails, so having a diverse path for management isn’t as useful as one might think. The usual failure modes will see a hypervisor crash or die, which will cause the whole VM to have to restart or be re-homed. Virtual switch failure is rare, and real switch failure typically means a few seconds out while traffic reroutes.
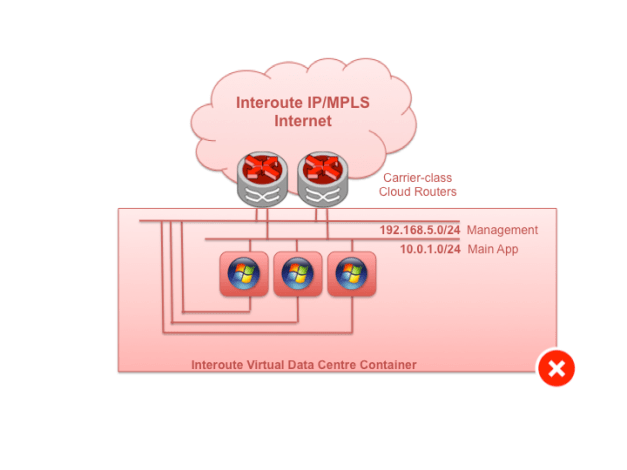
Fig 6. Try not to do it: multi-homing VMs
If you absolutely can’t live without a backside NIC for management or other access and your VM is based on a standard OS that makes no provision for this, avoid any additional static routing on the alternate interface. Access the VM through a proxy function on another VM. This way you don’t need to maintain the routing table on the host and the asymmetrical routing problem goes away. The alternate interface can be considered what network guys call, link-local scope only, as in – it doesn’t have a gateway.
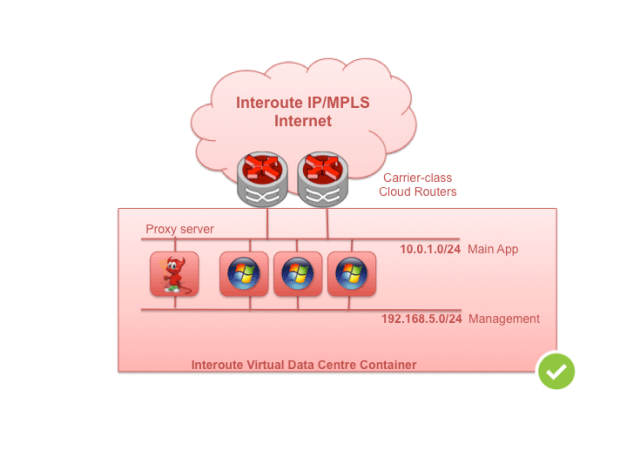
Fig 7. Better: use a proxy server
Interoute’s VDC gets you off to a flying start with either private network or public Internet topologies. Unlike most cloud providers, there’s no need to spend time defining over-the-top tunnel configurations to connect different sites together. And where you need more than a simple direct connection to a private network, such as in Internet scenarios, a fully-featured VM-based cloud router, or VNF, can be a powerful tool. Unlike in physical environments though, where network functions are expensively implemented, often on custom hardware and thus shared amongst as many client hosts as possible, virtual network functions share the same pool of resources – CPU, RAM, I/O – as our mainstream apps. Applying some of the simple steps listed here helps us make the most of mixed network and compute environments.
One of the more significant DDoS-related threats enjoying a renaissance in recent times is the UDP-based attack. In contrast to TCP – the reliable bitstream transfer protocol which dominates the Internet and underpins most web applications – UDP has quite different characteristics. It’s generally best suited to lightweight request-response type applications that require a simple record-delimited method to talk to a peer, with or without data integrity checks. UDP is also well suited to real-time media applications where retransmission of audio/video codec samples is too costly on latency and jitter.
The reason that UDP is attractive for DDoS purposes though, is it’s lightweight session setup. Compared with TCP where both endpoints must synchronise state – involving a randomly generated sequence number – before sharing data, UDP peers require no such invitation. Applications can simply send data, whether its expected or not, and the receiver has to deal with it. Indeed malicious applications can send large amounts of data to a receiver, faking their source address to make tracing difficult, and causing excessive resource consumption to the receiving victim.

Spoofed Source Address Attack
In more complex attacks, malicious actors can make use of imbalanced UDP protocols – ones where a small request can result in a large response – and, by again faking the source address to that of their victim, have an innocent third-party, or more likely many innocent third-parties, create a burden of traffic through reflection for the victim.

Reflected Attack
Besides UDP’s lack of requirement for initial connection and state synchronisation, the one thing that makes these two attack vectors possible is the ability to spoof packets, and specifically, spoof the IP address that one is communicating from. To a layman the ability to lie about one’s identity (or routing indicator, at least) might seem a bit of a schoolboy error on the parts of our Internet forefathers, but it stems from a time when the Internet trust model was quite different to what it is today.
The Internet community have strived to remove this particular avenue of exploit: the IETF published RFC 2827 – now established as BCP 38 – in 2000, and network equipment manufacturers have since deployed features to implement BCP 38 in modern routing gear. In summary, BCP 38 tell us that when a router forwards a packet, rather than simply routing based on the destination address, it should also check the source address and consider whether traffic routed to that source address would be sent via the interface that the packet was received on. More details here.
The logic is quite simple, but it enforces a symmetrical routing model which when applied to the edge of a network should result in an Internet topology where a lot more assurances can be made about the source address.
But lots of service providers have been slow and lethargic to adopt. It’s not totally surprising because the mitigating measures aren’t exactly without consequence. Because of the symmetrical routing model, the measures must really only be applied at the network edge, where asymmetric routing isn’t an accepted norm. Deep inside BGP-running ISP cores, dynamic routing protocols – the staple of a highly-available Internet – mean that asymmetry is much more common-place and deploying BCP 38 mechanisms on an interface with dynamic routing information can effectively cause a black-out as legitimate traffic is blocked.
Originally, many people thought that wide BCP 38 deployment was needed on the access networks that service consumer and residential broadband access, since these are the places where malware can fester in older PCs with out-of-date software. More modern thinking has made us realise that the almost universal proliferation of source-based NAT (network address translation) – a method for preserving IP address usage – is effectively doing a good BCP 38-like job for most broadband interfaces.
That leaves, then, the co-location and hosted Internet services. Because these sites usually publish content, they’re rarely subjected to source-based NAT, and malware infected servers in these areas could quite easily spoof addresses and contribute to the DDoS problem.
At Interoute, with our investment in Virtual Data Centre technology closely fused with our backbone IP network, this has been a particular concern for us. The advent of utility computing has brought with it commonplace try-before-you-buy trial schemes for cloud compute that are ripe for abuse by the criminal classes of Internet society.
Like many, we’ve not been squeaky-clean on our deployment of BCP 38 to prevent source address spoofing, and while our Juniper MX platforms support RPF – Reverse Path Filtering – configuration to achieve our objective, the challenge for our NOC operators is twofold: balancing the significant labour-intensive reconfiguration activity with other more overt activities, and ensuring against any misconfiguration of RPF and its painful consequences.
What we’ve really needed is an assisting tool for our Juniper MX-960 based backbone that would quickly audit the interfaces on a device and identify those that can accept BCP 38 filtering without consequence, and optionally go and configure them thus. For safety’s sake, we’d also want a way that we could quickly de-configure the feature in order to respond to any resulting code-brown moments.
Enter JUNOS SLAX op scripts, and rpf-tool – a tool that I’ve been trialling recently for its suitability in this role. Written in Juniper’s rather polarising hybrid XML / Perl / C language SLAX which I’ve written about before, rpf-tool aims to do exactly what’s needed.
Primarily, we can run the tool to get a list of interfaces that should and shouldn’t have RPF deployed. On my sample virtual Firefly, for instance, that looks a bit like the following list of interfaces, where the plus (+) sign indicates that we’re good to go (be sure to scroll wide).
adamc@VirtualSRX> op rpf-tool Interface RPF analysis/configuration tool Flags: + eligible, - ineligible, * running, ! excluded Interface Instance Description Address/Config ! ge-0/0/0.0 CST 10M FOOB1/CPE/12345 + ge-0/0/1.1 CST 10M FOOB1/CPE/10001 inet 10.0.1.1/24 + ge-0/0/1.2 CST 10M FOOB1/CPE/10002 inet6 fd00:0001::1/64 + ge-0/0/1.3 CST 10M FOOB1/CPE/10003 inet 10.0.3.1/24 inet6 fd00:0003::1/64 + ge-0/0/1.4 CST 10M FOOB1/CPE/10004 inet 10.0.4.1/24 inet 10.1.4.1/24 inet 10.2.4.1/24 inet6 fd00:0004::1/64 inet6 fd00:0104::1/64 inet6 fd00:0204::1/64 + ge-0/0/1.5 VPN-1 CST 10M FOOB1/CPE/10005 inet 10.0.5.1/24 + ge-0/0/1.6 VPN-1 CST 10M FOOB1/CPE/10006 inet6 fd00:0006::1/64 + ge-0/0/1.7 VPN-1 CST 10M FOOB1/CPE/10007 inet 10.0.7.1/24 inet6 fd00:0007::1/64 + ge-0/0/1.8 VPN-1 CST 10M FOOB1/CPE/10008 inet 10.0.8.1/24 inet 10.1.8.1/24 inet 10.2.8.1/24 inet6 fd00:0008::1/64 inet6 fd00:0108::1/64 inet6 fd00:0208::1/64
Note that the tool looks at interfaces regardless of whether they are related to the global table or a VRF routing instance. This is significant because by the time we get to a global table interface, we might already have a dynamic protocol involved.
Moving further down the test list of interfaces, we spot OSPF running, which disqualifies these interfaces. If we have OSPF running on an interface, we don’t have a guarantee that we’re going to symmetrically route back to the addresses we see sourced from the interface.
- ge-0/0/1.9 CST 10M FOOB1/CPE/10009 inet 10.0.9.1/24 OSPF - ge-0/0/1.10 CST 10M FOOB1/CPE/10010 inet6 fd00:000a::1/64 OSPF - ge-0/0/1.11 CST 10M FOOB1/CPE/10011 inet 10.0.11.1/24 inet6 fd00:000b::1/64 OSPF - ge-0/0/1.12 CST 10M FOOB1/CPE/10012 inet 10.0.12.1/24 inet 10.1.12.1/24 inet 10.2.12.1/24 inet6 fd00:000c::1/64 inet6 fd00:010c::1/64 inet6 fd00:020c::1/64 OSPF - ge-0/0/1.13 VPN-2 CST 10M FOOB1/CPE/10013 inet 10.0.13.1/24 OSPF - ge-0/0/1.14 VPN-2 CST 10M FOOB1/CPE/10014 inet6 fd00:000e::1/64 OSPF - ge-0/0/1.15 VPN-2 CST 10M FOOB1/CPE/10015 inet 10.0.15.1/24 inet6 fd00:000f::1/64 OSPF - ge-0/0/1.16 VPN-2 CST 10M FOOB1/CPE/10016 inet 10.0.16.1/24 inet 10.1.16.1/24 inet 10.2.16.1/24 inet6 fd00:0010::1/64 inet6 fd00:0110::1/64 inet6 fd00:0210::1/64 OSPF
A bit further down the list, we see the same logic applied when we have a BGP relationship established on an interface. While the BGP configuration on JUNOS doesn’t allow us to directly determine the interface involved, the JUNOS SLAX facilities allow us to take the peer address and qualify it with the networks on the connected interfaces.
- ge-0/0/1.17 CST 10M FOOB1/CPE/10017 inet 10.0.17.1/24 BGP + ge-0/0/1.18 CST 10M FOOB1/CPE/10018 inet6 fd00:0012::1/64 - ge-0/0/1.19 CST 10M FOOB1/CPE/10019 inet 10.0.19.1/24 inet6 fd00:0013::1/64 BGP - ge-0/0/1.20 CST 10M FOOB1/CPE/10020 inet 10.0.20.1/24 inet 10.1.20.1/24 inet 10.2.20.1/24 inet6 fd00:0014::1/64 inet6 fd00:0114::1/64 inet6 fd00:0214::1/64 BGP - ge-0/0/1.21 VPN-3 CST 10M FOOB1/CPE/10021 inet 10.0.21.1/24 BGP + ge-0/0/1.22 VPN-3 CST 10M FOOB1/CPE/10022 inet6 fd00:0016::1/64 - ge-0/0/1.23 VPN-3 CST 10M FOOB1/CPE/10023 inet 10.0.23.1/24 inet6 fd00:0017::1/64 BGP - ge-0/0/1.24 VPN-3 CST 10M FOOB1/CPE/10024 inet 10.0.24.1/24 inet 10.1.24.1/24 inet 10.2.24.1/24 inet6 fd00:0018::1/64 inet6 fd00:0118::1/64 inet6 fd00:0218::1/64 BGP
And finally, we get the all important exclusion feature. We may not be able to rely on the tool to be able to determine every single interface that should be excluded from RPF, but we can at least give the operator a hook or a flag in order to warn the tool not to try to configure RPF on an interface. Built-in to the tool, we have several conditions that can force an exclusion:
The exclamation mark in the output indicates the exclusion.
adamc@VirtualSRX> op rpf-tool Interface RPF analysis/configuration tool Flags: + eligible, - ineligible, * running, ! excluded Interface Instance Description Address/Config ! ge-0/0/0.0 CST 10M FOOB1/CPE/12345 ! lo0.0 inet 127.0.0.1/32 inet 10.255.0.1/32 ! fxp0.0 (MGMT)
adamc@VirtualSRX> show configuration interfaces ge-0/0/0
description Main;
unit 0 {
description "CST 10M FOOB1/CPE/12345 X {no-rpf, if-acct} // Foobar Saunders and his Unix Entendres";
family inet {
dhcp;
}
}
Finally, after we’ve checked the list, we can either give rpf-tool the thumbs up to configure RPF on all eligible interfaces, or we can simply configure RPF on an interface by interface basis.
adamc@VirtualSRX> op rpf-tool mode apply Applying RPF inet configuration to interface ge-0/0/1.1 Applying RPF inet6 configuration to interface ge-0/0/1.2 Applying RPF inet configuration to interface ge-0/0/1.3 Applying RPF inet6 configuration to interface ge-0/0/1.3 Applying RPF inet configuration to interface ge-0/0/1.4 Applying RPF inet6 configuration to interface ge-0/0/1.4 Applying RPF inet configuration to interface ge-0/0/1.5 Applying RPF inet6 configuration to interface ge-0/0/1.6 Applying RPF inet configuration to interface ge-0/0/1.7 Applying RPF inet6 configuration to interface ge-0/0/1.7 Applying RPF inet configuration to interface ge-0/0/1.8 Applying RPF inet6 configuration to interface ge-0/0/1.8 Applying RPF inet6 configuration to interface ge-0/0/1.18 Applying RPF inet6 configuration to interface ge-0/0/1.22 Apply RPF to all interfaces: 10 interface(s) affected: 6 inet, 8 inet6
adamc@VirtualSRX> show system commit
0 2014-03-01 18:36:27 UTC by adamc via junoscript
Apply RPF to all interfaces: 10 interface(s) affected: 6 inet, 8 inet6
It’s useful to note that if we try to apply RPF on an interface that the tool thinks is inappropriate, it won’t do it. In this case, ge-0/0/0.0 has got the magical description tag (it’s the management interface to my Firefly VM and I didn’t want to take any chances).
adamc@VirtualSRX> op rpf-tool mode apply interface ge-0/0/0.0 Interface ge-0/0/0.0 specifically excluded by local-policy-exclusions Apply RPF to interface: ge-0/0/0.0: 0 inet, 0 inet6 No affected interfaces: configuration not applied
And of course we need the emergency, “No! Turn it off!” switch, so we can quickly reverse any changes and problems caused by deploying RPF.
adamc@VirtualSRX> op rpf-tool mode remove Removing RPF inet configuration from interface ge-0/0/1.1 Removing RPF inet6 configuration from interface ge-0/0/1.2 Removing RPF inet configuration from interface ge-0/0/1.3 Removing RPF inet6 configuration from interface ge-0/0/1.3 Removing RPF inet configuration from interface ge-0/0/1.4 Removing RPF inet6 configuration from interface ge-0/0/1.4 Removing RPF inet configuration from interface ge-0/0/1.5 Removing RPF inet6 configuration from interface ge-0/0/1.6 Removing RPF inet configuration from interface ge-0/0/1.7 Removing RPF inet6 configuration from interface ge-0/0/1.7 Removing RPF inet configuration from interface ge-0/0/1.8 Removing RPF inet6 configuration from interface ge-0/0/1.8 Removing RPF inet6 configuration from interface ge-0/0/1.18 Removing RPF inet6 configuration from interface ge-0/0/1.22 Remove RPF from all interfaces: 10 interface(s) affected: 6 inet, 8 inet6
At this time, rpf-tool is still under testing and investigation at Interoute, but the whole Internet ISP community can benefit by the reduction in DDoS and address spoofing, so I encourage external experimentation and feedback. The code is available here for those willing to do so. All of the usual disclaimers apply, and explicitly I provide no warranty.
Update: For those of you reading this and looking to deploy Juniper’s RPF functionality on your MX-based network in order to implement BCP-38, it’s worth mentioning PR 873709: a particularly nasty defect that is triggered when you remove RPF from an interface, and another seemingly unrelated interface with RPF configured then stops forwarding. The situation can be remediated by removing RPF from the affected interface and re-adding it, and perhaps rpf-tool is useful in that regard. Most likely to stumble onto this on a box with lots of FPCs and lots of logical interfaces. Juniper also document an interesting mitigating step which is to reboot the REs with a flag in the boot loader that prevents the situation of overlapping squashed interface indices:
debug.pfe_local_idx_override=1
Obviously, you’re on your own with that one!

Dealing with the fall-out of Shellshock
So while most of the world was going crazy reading all the news about ShellShock – the weakness in the GNU bash shell tool used by versions of the Linux operating system around the world – I was locked away in a customer software development workshop all day.
When I finally came out, a lot of the hubbub had died down after it had been announced that several of the security equipment vendors had apparently issued IPS rules and signatures that might catch the pesky thing.
Of course the difficulty with Shell Shock is that we’re all still coming to terms with the fact that rather than this being a clearly scoped remote network vulnerability in a poorly implemented network service, or even an impractical protocol design, the weakness actually affects the basic interprocess communication systems inherent within the UNIX – Linux – operating system.
In contrast to the usual security vulnerabilities seen, we can’t simply audit the version of the network software involved to tell if we’re affected – we have to actually understand how the network software does what it does to achieve its effects, and whether it makes use of the underlying operating system shell and how its network interactions might influence that.
Because of these complexities, determining exact scope of vulnerability is significantly difficult. As I write, security experts suggest that the following network services and protocols may have potential exposure:
However, there’s no guarantee of the completeness of that list, and determining whether a specific situation might cause exposure is an expensive activity.
Should we breathe a sigh of relief, then, when the security appliance vendors publish IPS rules? The respected Vulnerability Research Team who source rules for Sourcefire and Cisco amongst others, published four rules which focus on the web server CGI situation and look for the explicit attempt which has been seen in the wild.
But in contrast to, say, the Heartbleed problem which was a clear case of a protocol violation that a network security device could be programmed to spot, Shell-Shock is much harder. It’s quite trivial, for example, for someone in possession of the VRT rules to modify the commonly available exploits so that the literal IPS rule match fails, but the semantics of the network exchange result in the same exposure.
So what’s the answer? There seem to be various patches available to repair bash, but some have called into question the effectiveness of these patches. Others have suggested abandoning the bash shell as the system default and use more modern alternatives such as dash.
For those not able to make such significant changes to the fundamental parts of the operating system shell, however, there is an alternative method to protect certain network apps using Linux’s comprehensive dynamic linking technology:
Given a network application that might invoke system shell commands, it’s possible to trap attempts by that application to set environment variables – which are the crux of the weakness – and vet the modifications against a regular expression. If the attempted environmental variables look sane and match the regular expression, the operation is permitted, but if the environmental variables don’t match, then the operation is denied.
This can be considered a kind-of UNIX inter-process communication firewall in policing the communications between the essential components of a UNIX-based solution.
Inspired by Fabio Busatto’s libkeeaplive package, which enables network applications to transparently make use of implicit socket keepalives with modifications, I can present, without warranty, libbunker.so (Shellshock? Sorry!) – a framework for policing the environmental variables communicated between UNIX processes:
/*
* Simple wrapper around setenv in order to police
* environment setting operations so that downstream
* bash shells cannot be subverted into running arbitrary
* code. adamc 26-Sep-2014.
*
* Inspired by Fabio Busatto's libkeepalive
*
* # compile like this:
* linux# gcc -shared -o libbunker.so -ldl bunker.c
* linux# cp libbunker.so /usr/lib
*
* # protect apps like this:
* linux$ LD_PRELOAD=/usr/lib/libbunker.so /usr/local/bin/my-network-app
*/
#ifndef RTLD_NEXT
# define _GNU_SOURCE
#endif
#include <dlfcn.h>
#include <errno.h>
#include <stdlib.h>
#include <strings.h>
#include <sys/types.h>
#include <regex.h>
int setenv(const char *name, const char *value, int overwrite);
int setenv(const char *name, const char *value, int overwrite) {
int (*libc_setenv)(const char*, const char*, int overwrite);
int result;
regex_t re;
*(void **)(&libc_setenv) = dlsym(RTLD_NEXT, "setenv");
if(dlerror()) {
errno = EACCES;
return -1;
}
/* Ensure the value of the variables contains only letters,
* numbers and selected characters. You may need to modify this
* if it is too restrictive.
*/
result = regcomp(&re, "^[0-9a-z\\ \\_\\-\\:\\,]+$",
REG_EXTENDED|REG_ICASE);
if (result!=0) {
errno = EINVAL;
return -1;
}
result = regexec(&re, value, 0, NULL, 0); regfree(&re);
if (result!=0) {
errno = EINVAL;
return -1;
}
return libc_setenv(name, value, overwrite);
}

Juniper’s SLAX needn’t be a dark art
At Interoute, we make extensive use of Juniper’s MX-960 platform to support enterprise and service provider business on a uniform packet network. A mature and established platform, the MX-960 is a solid workhorse for the usual suite of IP-based services offered by most providers: Internet access/transit, IP VPN, VPLS. JUNOS has persisting roots in FreeBSD and the core of Juniper’s routing architecture, rpd, has a respected heritage in the original UNIX gated – probably one of the earliest UNIX software programs to make use of asynchronous I/O in order to provide the facility to execute multiple concurrent tasks at the same time without resorting to UNIX processes.
For a long time, I’ve wanted to post an article about the options available for those seeking to establish a high-availability, geographically diverse web presence.
The flexibility with which we can turn up and down Internet-connected compute power using virtualisation is one thing, but what considerations must we take into account in order to achieve the resilience and high-availability expected in today’s web sites and services?
I got the necessary kick in the backside I needed in December when F5 Networks refreshed the pricing schedule for the virtual version of their LTM/GTS suite and specifically included a lab version.
If you’re responsible for Information Security in your organisation and I told you that your users will violate your hard-grafted corporate IT security policy and surrender their usernames and passwords to an external uncontrolled website, you might think I was confused. Continue reading…
If you’ve used your home BT broadband in the UK over the last two weeks, you’ve very probably been an unwitting pioneer of the next-generation of Internet transport technology! Earlier this week, the London Internet Exchange (LINX) announced that they had successfully deployed their first 100Gbps production ports to members, and the first users of this are BT in order to provide a significant upgrade to their intra-UK ISP connectivity prior to the Olympic games, which makes good sense. Continue reading…
Without doubt, there can be few tools that parallel the usefulness and diagnostic ability of traceroute and ping. These tools offer invaluable insight into the operation and performance of network elements that we take for granted in today’s use of the Internet. Whether it’s a case of trying to discover why your laptop wifi or home broadband is not working, or why the office laser printer is not working, tech-savvy users and network engineers alike have long been acquainted with the use of these tools in order to pinpoint problems.
The same goes for network trouble-shooting in large-scale ISP networks. The principles are the same, even if the interface bandwidths are slightly different. Recently, though, I was offered a stark reminder of just how dependent today’s large-scale ISP networks are on link aggregation technology, and how a technology that makes simple promises can be complicated underneath. Continue reading…
I’ve spent the weekend beta-testing Interoute’s exciting new Virtual Data Centre proposition and I feel compelled to share my experiences. VDC, as its known internally at Interoute, is a recent technology development from the development group based in London. It attempts to fuse the flexibility and elasticity of public cloud computing offerings, with the home-territory of Enterprise VPN business to which Interoute’s dense IP/MPLS network has always been strong and dependable, having arguably pioneering MPLS VPN technology in Europe. As a well-known critic of poor implementations of virtualisation technology within Interoute, I was invited to participate in an early beta trial and comment freely. Continue reading…
